AWS Lambda와 selenium을 이용해서 날씨알림봇 만들기
- 목차
2024.04.22 - [AWS] - AWS Lambda만을 이용해서 날씨알림봇 만들기
0. 배경
매일 아침 일어나면 오늘은 비가 올 것인지, 기온은 어떤지를 확인해본다. 그런데 이상하다. 제공사마다 강수확률과 기온이 다르다. 네이버에서는 제공사를 선택할 수 있도록 되어있지만 한눈에 파악하기는 어렵다.

여러 제공사의 기상 정보를 한데 모아서 볼 수는 없을까 생각하다 데이터를 스크랩하여 테이블로 만들고 메일로 보내면 어떨까 싶었다. 첫 아이디어는 이랬다.

날씨 데이터를 스크랩한 후 테이블을 만들어 이미지로 떨구는 `script.py`를 만들고 이를 실행하는 `bat` 파일을 만들어 윈도우 작업 스케줄러에 매일 아침에 실행하도록 설정해둔다. 그렇게 이미지가 생성되면 그걸 이벤트로 받아 power automate가 해당 이미지를 첨부하여 나에게 메일을 보내도록 하였다. 이렇게 했을 때 단점은 컴퓨터가 아침에 켜져 있어야 한다는 것!
이건 정말 아닌 것 같아서 스크립트 짜두고 약 1년이 흐르고... 문득 생각이 들었다. 왜 여태 lambda를 안 썼지?
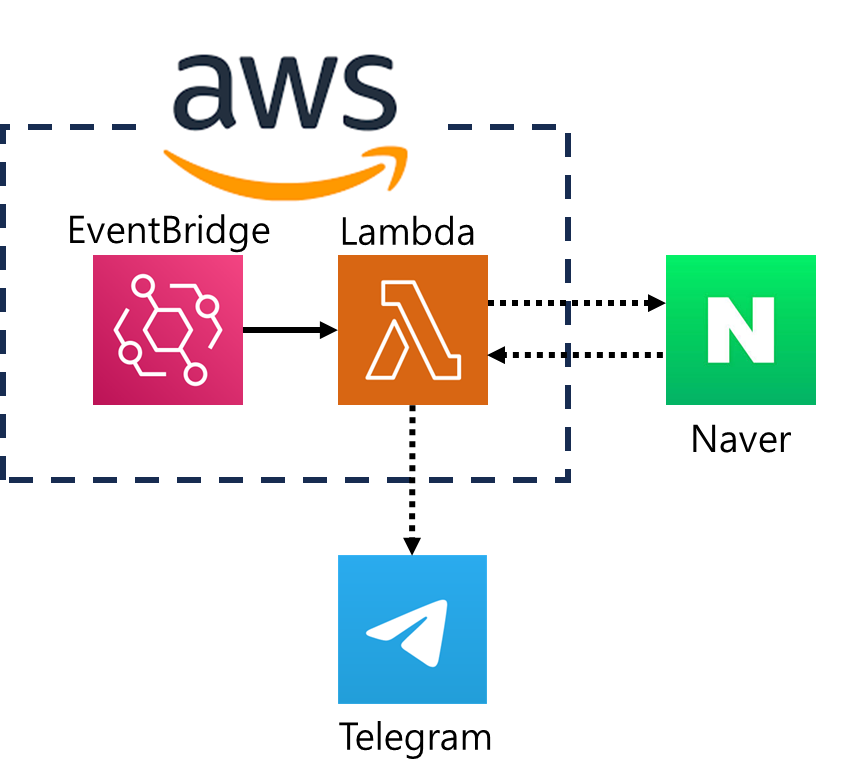
그리하여 이런 모양이 되었다. EventBridge로 주기적으로 Lambda를 실행하며, Lambda에서는 날씨 데이터를 가져온 뒤 텔레그램 봇을 통해 나에게 메시지를 전달한다.
텔레그램을 선택한 이유는
1. 무료다.
2. 봇 생성이 쉽다.
3. API를 다루기 쉽다.
카톡봇, 팀즈웹훅도 고려해봤는데 카톡은 봇 생성하려면 신청 절차가 필요해서 그만뒀고, 팀즈 웹훅은 개인 사용자는 못 써서 포기했다. 그 외 디스코드봇 등도 있지만 접근성 측면에서 텔레그램이 더 적절하다고 생각했다.
1. 텔레그램 봇 만들기
1-1. 봇파더(BotFather)
텔레그램에서 BotFather를 찾아주자. 이 때 가짜들도 많으니 인증마크가 있는 걸로 골라주자.
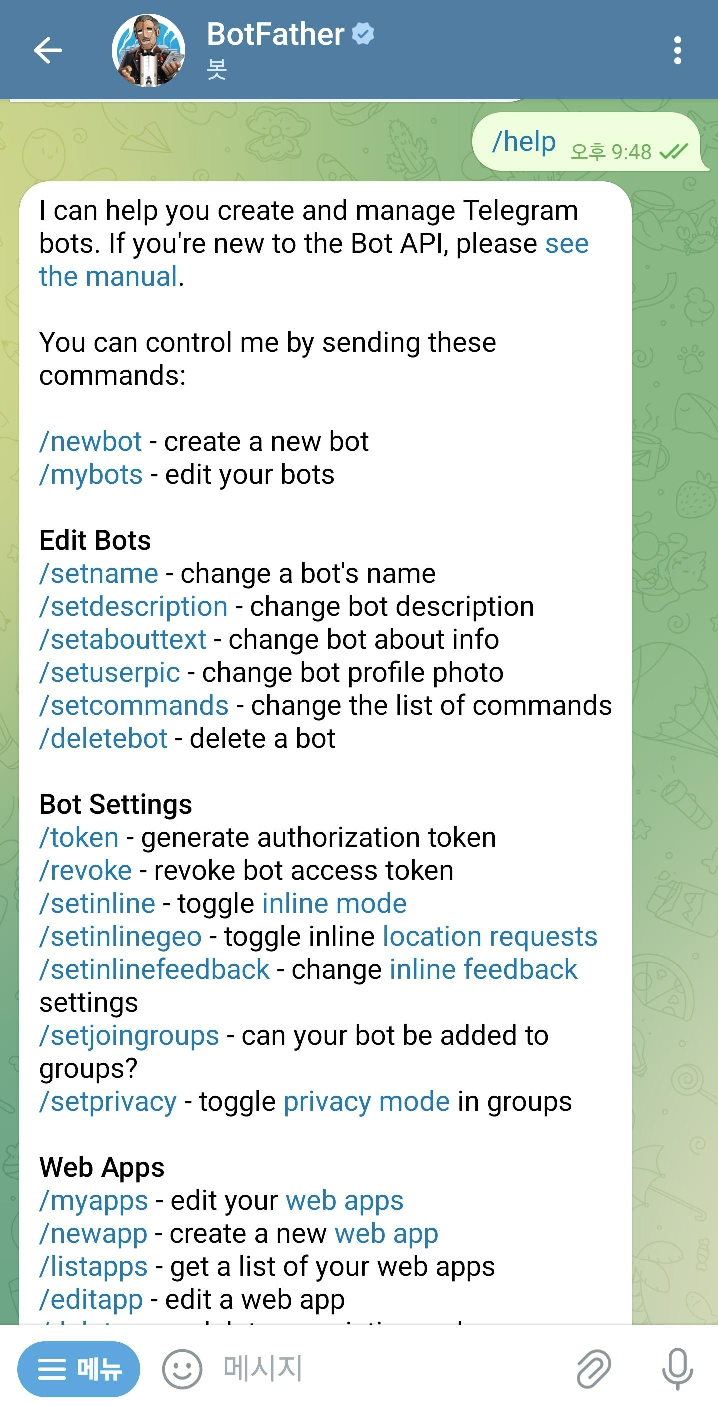
여기서 `/newbot`을 입력하여 새로운 봇을 만들어준다.

그러면 봇 이름을 설정하라고 한다. 텔레그램에 표시되는 이름으로 중복도 가능하다.
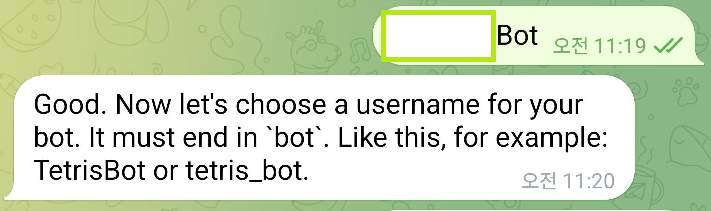
다음으로는 유저명(아이디)을 설정하라고 한다. 이건 `bot`으로 끝나야만 하며 중복도 되지 않는다.
중복된 유저명을 설정하면 아래와 같은 안내가 나온다.

그래서 중복되지 않는 다른 유저명을 입력하면 봇 생성이 완료된다.

1-2. 메시지 보내기 테스트
파더봇이 알려주는 `t.me/{username}` 링크로 접속하면 내가 만든 봇과 대화를 시작할 수 있다. API를 통해 채팅방에 메시지를 보내기 위해서는 방 번호가 필요하기 때문에 아무 채팅이나 던진 뒤 다음 API를 호출해보자.
`https://api.telegram.org/bot{token}/getUpdates`
봇을 만들 때 생성되었던 토큰 값을 `token`에 넣어서 API를 호출하면 채팅방의 id를 확인할 수 있다.
이후 아래와 같은 코드로 채팅방에 메시지를 보낼 수 있다.
import requests
TOKEN = 'YOUR_TOKEN'
url = "https://api.telegram.org/bot{}/sendMessage".format(TOKEN)
payload = {
"text": text,
"chat_id": chat_id
}
requests.post(url, payload)
2. 날씨 정보 스크랩
네이버 날씨가 반응형 웹이기 때문에 `BeautifulSoup`만으로는 스크랩이 안 되고, 어쩔 수 없이 `selenium`을 써야한다. 굳이 네이버에서 날씨를 수집하지 않고 기상청 API나 다른 회사들의 API를 써서 직접 수집하겠다고 하면 불필요할 수도 있다. 근데 기상청을 제외한 곳들은 API를 제공하지 않거나 제공하더라도 제한적 무료 혹은 유료이고, 제공사마다 API 양식이 다르기 때문에 네이버에서 날씨를 수집하는 게 더 편할 수 있겠다고 생각했다.
import pandas as pd
import time
import datetime
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
d_today = datetime.date.today()
executable_path = 'chromedriver.exe'
chrome_options = Options()
chrome_options.add_argument("--headless")
result = pd.DataFrame()
forecast_kor = {'KMA': '기상청', 'ACCUWEATHER': '아큐웨더',
'TWC': '웨더채널', 'WEATHERNEWS': '웨더뉴스'}
# 데이터 수집
for forecast in forecast_kor.keys():
driver = webdriver.Chrome(options=chrome_options)
url = 'https://weather.naver.com/today/?cpName={}'.format(forecast)
driver.get(url)
time.sleep(1)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
weather_data = soup.find_all(attrs={'class': 'top'})
ymdt = [a['data-ymdt'] for a in weather_data]
temp = [int(a['data-tmpr']) for a in weather_data]
weather_data = soup.find(attrs={'class': 'weather_table_wrap'})
rain_prob = []
rain_amount = []
for t in ymdt:
rain = weather_data.find_all(attrs={'data-ymdt': t})
prob = rain[1].text.strip()
amount = rain[2].text.strip()
if '~1' == amount:
amount = '0.5'
rain_prob.append(prob)
rain_amount.append(amount)
ymdt_col = [f'{t[:4]}년 {t[4:6]}월 {t[6:8]}일 {t[8:]}시' for t in ymdt]
tmp = pd.DataFrame([temp, rain_prob, rain_amount], columns=ymdt_col, index=[
[forecast_kor[forecast] for _ in range(3)], ['기온', '강수확률', '강수량']])
tmp.index.names = ['제공사', '날씨']
result = pd.concat([result, tmp], axis=0)
driver.close()
# 데이터 정제
d_today_last = f'{d_today.year}년 {d_today.month:02d}월 {d_today.day:02d}일 23시'
time_today = [t for t in result.columns if t <= d_today_last]
r = result[time_today].copy().astype(str)
for forecast in forecast_kor.values():
r.loc[(forecast, ['기온']), ['최저']] = r.loc[(forecast, ['기온']),
:d_today_last].replace('nan', np.nan).dropna(axis=1).astype(int).min(axis=1).astype(str)
r.loc[(forecast, ['기온']), ['최고']] = r.loc[(forecast, ['기온']),
:d_today_last].replace('nan', np.nan).dropna(axis=1).astype(int).max(axis=1).astype(str)
r.loc[(forecast, ['강수확률', '강수량']), '최저'] = '-'
r.loc[(forecast, ['강수확률', '강수량']), '최고'] = '-'
index = [f'{d_today.year}년', f'{d_today.month}월 {d_today.day}일']
r.columns = [t[-3:] for t in r.columns]
r.index.names = index네이버가 워낙 깔끔하게 html 코드를 짜놓아서 데이터를 수집하는 건 어렵지 않다. 다만 약간의 데이터 정제를 해줘야 한다.
1. 내일과 모레 날씨도 함께 수집되지만 나는 오늘 날씨만 필요하기 때문에 데이터를 당일 23시까지로 제한한다.
2. 기상청 데이터의 경우, 최근 5시간의 강수확률을 제공하지 않는다. 그래서 데이터가 `-`로 들어오고, 때문에 `astype(str)`을 해주는 게 좋다.
3. 텔레그램에 메시지 보내기
데이터를 수집하고 정제까지 완료했다면 만들어진 표를 Lambda를 통해 텔레그램으로 전송해야 한다. 이 때 몇가지 난관이 있었다.
3-1. Lambda에 Selenium 설치하기
Lambda에서 selenium이 돌아가도록 어떻게 만들지 싶었다. (요즘 selenium은 필요 없다지만) chromedriver는 어떻게 설치하고 무슨 버전을 받아야 하며 등등... 한 가지 확실한 건 절대 lambda만으론 안 되고 ECR을 써서 컨테이너를 만들어야 한다는 것이었다. 여러모로 고민이었는데 무려! 은인께서 github에 정리해서 올려놓으셨다. 심지어 최근까지도 계속 업데이트가 되는 중이다.
https://github.com/umihico/docker-selenium-lambda
위 github에 있는 `Dockerfile`과 `main.py`를 참고하여 쉽게 Lambda용 컨테이너를 만들 수 있었다.
(컨테이너를 만들고 Lambda에서 사용하는 방법은 AWS Cloud9과 ECR을 이용하여 Lambda Container 배포하기 참고!)
▼ `Dockerfile`
FROM public.ecr.aws/lambda/python@sha256:6db34bc7b73e25ae2fdb2421815805cd404ae4c0f46bcc336c677ea40f901877 as build
RUN dnf install -y unzip && \
curl -Lo "/tmp/chromedriver-linux64.zip" "https://storage.googleapis.com/chrome-for-testing-public/122.0.6261.69/linux64/chromedriver-linux64.zip" && \
curl -Lo "/tmp/chrome-linux64.zip" "https://storage.googleapis.com/chrome-for-testing-public/122.0.6261.69/linux64/chrome-linux64.zip" && \
unzip /tmp/chromedriver-linux64.zip -d /opt/ && \
unzip /tmp/chrome-linux64.zip -d /opt/
FROM public.ecr.aws/lambda/python@sha256:6db34bc7b73e25ae2fdb2421815805cd404ae4c0f46bcc336c677ea40f901877
RUN dnf install -y atk cups-libs gtk3 libXcomposite alsa-lib \
libXcursor libXdamage libXext libXi libXrandr libXScrnSaver \
libXtst pango at-spi2-atk libXt xorg-x11-server-Xvfb \
xorg-x11-xauth dbus-glib dbus-glib-devel nss mesa-libgbm
RUN pip install selenium==4.18.1
COPY --from=build /opt/chrome-linux64 /opt/chrome
COPY --from=build /opt/chromedriver-linux64 /opt/
COPY main.py ./
CMD [ "main.handler" ]
▼ `main.py`
from selenium import webdriver
from tempfile import mkdtemp
from selenium.webdriver.common.by import By
def handler(event=None, context=None):
options = webdriver.ChromeOptions()
service = webdriver.ChromeService("/opt/chromedriver")
options.binary_location = '/opt/chrome/chrome'
options.add_argument("--headless=new")
options.add_argument('--no-sandbox')
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--single-process")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-dev-tools")
options.add_argument("--no-zygote")
options.add_argument(f"--user-data-dir={mkdtemp()}")
options.add_argument(f"--data-path={mkdtemp()}")
options.add_argument(f"--disk-cache-dir={mkdtemp()}")
options.add_argument("--remote-debugging-port=9222")
chrome = webdriver.Chrome(options=options, service=service)
chrome.get("https://example.com/")
return chrome.find_element(by=By.XPATH, value="//html").text
3-2. Lambda에서 메시지 전송하기
처음엔 "표를 이미지로 떨군 다음에 전송해볼까?" 하고 생각했다. 하지만 데이터를 수집하고 메시지를 전송하는데 필수적인 `selenium`, `pandas`, `beautifulsoup4`, `lxml`, `requests`을 설치하고 추가적으로 `matplotlib`을 설치하는 순간 Cloud9 EC2의 용량이 꽉 차서 Docker를 만드는데 실패했다는 메시지가 떠버렸다. 이를 해결하려면 EC2의 EBS 용량을 늘려야 하는데 이것도 비용이라서 다른 방법이 있는지를 찾는 걸 우선하였다.
차선으로 표 자체를 전송하면 어떨까 싶었다. 하지만 텔레그램에는 표를 전송하는 기능이 없었고, 인터넷 검색을 해보면 대부분 markdown 형식의 표로 변환해서 넘기고 있었다. 다행스럽게도 `pandas`에서 `tabulate` 패키지만 추가로 설치하면 `to_markdown()`을 통해 markdown 형식의 표로 바꿀 수 있었다. 거기에 더 예쁜 모양을 위해 `to_markdown(tablefmt="grid")`를 해주었다.
이렇게 했을 때의 새로운 문제는 표가 가로로 길면 표 모양이 깨진다는 것이었다! 텔레그램 내에서 표가 안 깨질 정도로 컬럼 수를 조정하여 여러 번 나눠 메시지를 보내야했다. 또, 표 앞뒤로 `<pre>` `</pre>`를 넣어 최대한 표가 안 깨지도록 하며 텔레그램 API 인수에 `"parse_mode":"HTML"`을 넣어주었다.
참고
텔레그램 메시지 당 길이 제한이 있어, 표를 하나의 메시지에 넣어서 보내는 것보다 여러 번 나눠 보내는 게 좋다.
▼ `main.py`
from selenium import webdriver
from tempfile import mkdtemp
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import datetime
import time
import json
import os
import requests
TOKEN = os.environ['TOKEN']
CHAT_ID = os.environ['CHAT_ID']
TELEGRAM_URL = "https://api.telegram.org/bot{}/sendMessage".format(TOKEN)
def handler(event=None, context=None):
options = webdriver.ChromeOptions()
service = webdriver.ChromeService("/opt/chromedriver")
options.binary_location = '/opt/chrome/chrome'
options.add_argument("--headless=new")
options.add_argument('--no-sandbox')
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--single-process")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-dev-tools")
options.add_argument("--no-zygote")
options.add_argument(f"--user-data-dir={mkdtemp()}")
options.add_argument(f"--data-path={mkdtemp()}")
options.add_argument(f"--disk-cache-dir={mkdtemp()}")
options.add_argument("--remote-debugging-port=9222")
d_today = datetime.datetime.now() + datetime.timedelta(hours=9)
result = pd.DataFrame()
forecast_kor = {'KMA': '기상청', 'ACCUWEATHER': '아큐웨더',
'TWC': '웨더채널', 'WEATHERNEWS': '웨더뉴스'}
for forecast in forecast_kor.keys():
driver = webdriver.Chrome(options=options, service=service)
url = 'https://weather.naver.com/today/?cpName={}'.format(forecast)
driver.get(url)
time.sleep(1)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
weather_data = soup.find_all(attrs={'class': 'top'})
ymdt = [a['data-ymdt'] for a in weather_data]
temp = [int(a['data-tmpr']) for a in weather_data]
weather_data = soup.find(attrs={'class': 'weather_table_wrap'})
rain_prob = []
rain_amount = []
for t in ymdt:
rain = weather_data.find_all(attrs={'data-ymdt': t})
prob = rain[1].text.strip()
amount = rain[2].text.strip()
if '~1' == amount:
amount = '0.5'
rain_prob.append(prob)
rain_amount.append(amount)
ymdt_col = [f'{t[:4]}년 {t[4:6]}월 {t[6:8]}일 {t[8:]}시' for t in ymdt]
tmp = pd.DataFrame([temp, rain_prob, rain_amount], columns=ymdt_col, index=[
[forecast_kor[forecast] for _ in range(3)], ['기온', '강수확률', '강수량']])
tmp.index.names = ['제공사', '날씨']
result = pd.concat([result, tmp], axis=0)
driver.close()
d_today_last = f'{d_today.year}년 {d_today.month:02d}월 {d_today.day:02d}일 23시'
time_today = [t for t in result.columns if t <= d_today_last]
r = result[time_today].copy().astype(str)
for forecast in forecast_kor.values():
r.loc[(forecast, ['기온']), ['최저']] = r.loc[(forecast, ['기온']),
:d_today_last].replace('nan', np.nan).dropna(axis=1).astype(int).min(axis=1).astype(str)
r.loc[(forecast, ['기온']), ['최고']] = r.loc[(forecast, ['기온']),
:d_today_last].replace('nan', np.nan).dropna(axis=1).astype(int).max(axis=1).astype(str)
r.loc[(forecast, ['강수확률', '강수량']), '최저'] = '-'
r.loc[(forecast, ['강수확률', '강수량']), '최고'] = '-'
index = [f'{d_today.year}년', f'{d_today.month}월 {d_today.day}일']
r.columns = [t[-3:] for t in r.columns]
r.index.names = index
order_where = ['기상청', '아큐웨더', '웨더채널', '웨더뉴스']
order_index = ['기온', '강수확률', '강수량']
for i in range(0, len(r.columns), 3):
tmp = r.iloc[:, i:i+3].reset_index()
tmp[index[0]] = pd.Categorical(tmp[index[0]], categories=order_where, ordered=True)
tmp[index[1]] = pd.Categorical(tmp[index[1]], categories=order_index, ordered=True)
tmp = tmp.sort_values(by=[index[1], index[0]])
if i == 0:
msg = '<b>날씨 알림</b>'
else:
msg = ''
msg += f'<pre>{tmp.to_markdown(index=None, tablefmt="grid")}</pre>'
try:
payload = {
"text": msg,
"chat_id": CHAT_ID,
"parse_mode":"HTML"
}
response = json.loads(requests.post(TELEGRAM_URL, payload).text)
if not response['ok']:
raise Exception(response['description'])
except Exception as e:
raise e
return {"status":"OK"}- `os.environ['TOKEN']`으로 Lambda에 등록한 환경 변수를 가져온다. 환경변수는 Lambda 함수 - [구성] - [환경 변수]에서 편집할 수 있다.

- `d_today = datetime.datetime.now() + datetime.timedelta(hours=9)`: Lambda 특성상 타임존이 UTC로 되어있기 때문에, 한국 시간에 맞춰주려면 +9시간을 해줘야 한다.

그러면 이렇게 (그나마) 깔끔한 표 형태로 텔레그램에 메시지가 날라오는 걸 확인할 수 있다.
3-3. EventBridge 설정
EventBridge에서 [Scheduler] - [일정]에서 일정 생성을 할 수 있다. 나는 반복 일정으로 설정하여 월~금 오전 6시, 오후 12시에 날씨를 알림을 받길 원했기 때문에 다음과 같이 설정했다.
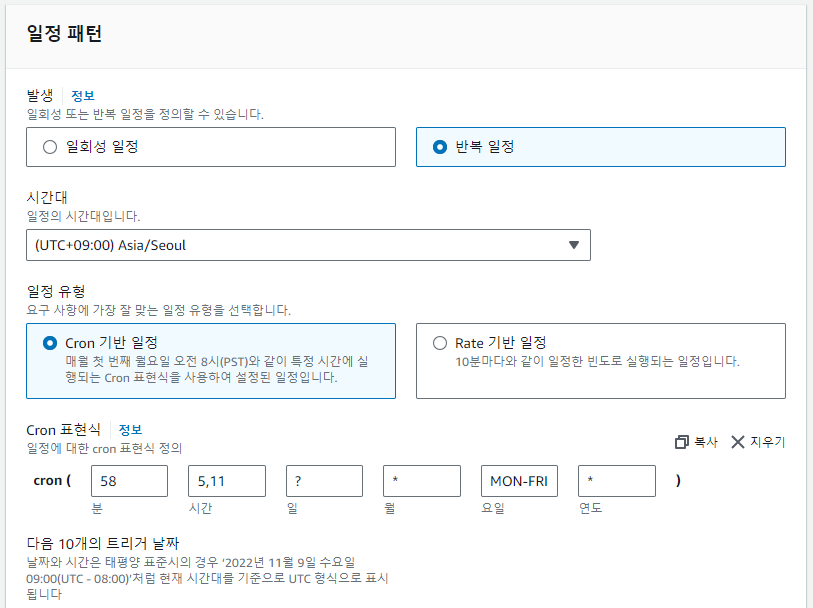
Cron 표현식은 한 번 이해하면 쉽게 만들 수 있지만 이해하기가 까다롭다. 잘 모르겠으면 AWS 문서를 확인해보자.
https://docs.aws.amazon.com/ko_kr/autoscaling/application/userguide/scheduled-scaling-using-cron-expressions.html

어쨌든 6시, 12시에 날씨를 받아보기 위해 5시 58분, 11시 58분에 람다가 작동하도록 설정했다.
다음으로 대상 선택에서 작성했던 lambda 함수를 선택해준다. 여기서는 딱히 인자가 필요없기 때문에 페이로드는 빈칸으로 남겨두었다.
이렇게 모든 과정이 끝나 날씨 알림을 받을 수 있게 되었다.
4. 전체 소스 코드
'AWS' 카테고리의 다른 글
| AWS Lambda만을 이용해서 날씨알림봇 만들기 (0) | 2024.04.22 |
|---|---|
| AWS Lambda, API Gateway로 대화형 질답봇 만들기 (Feat. 야구) (0) | 2024.04.02 |
| AWS Cloud9과 ECR을 이용하여 Lambda Container 배포하기 (0) | 2024.02.23 |
| SageMaker Studio에서 영구적 가상환경 만들기 (0) | 2024.02.18 |
| AWS Lambda에 layer 추가하기 (추가 Package 설치) (0) | 2024.02.14 |



