머신러닝으로 야구 득/실점 예측해보기 (4) 데이터 저장
- 목차
반응형
한 달의 결과만 가져올 것이 아니고 (필요시) 한 팀의 데이터만 가져올 것이 아니기 때문에 다음과 같은 함수를 만들었다.
# url 가져오기
def geturl(date, teamname):
(year, month) = ym(date)
url = "https://sports.news.naver.com/kbaseball/schedule/index.nhn?&month="+str(month)+"&year="+str(year)+"&teamCode="+teamname
return url
# 날짜 자르기
def ym(date):
year = str(date)[:4]
month = str(date)[-2:]
return (year, month)이 이후 코드는 앞선 글들에서 확인할 수 있다.
pandas를 이용해서 엑셀 파일에 저장할 것이다.
import pandas as pd
import os
def regist(sc, df):
for (month, date, day, wdl, r, er, op) in sc:
l = len(df["DATE"])
df.loc[l] = [int(str(date_start)[:4]), month, date, day, wdl, r, er, op]
base_dir = 'C:/Users/Username/Desktop'
excel_file = "lotte.xlsx"
excel_dir = os.path.join(base_dir, excel_file)
df = pd.read_excel(excel_dir, encoding="EUC_KR")
year_list = [(200803, 200811), (200904, 200911), (201003, 201011), (201104, 201111), (201204, 201212), \
(201303, 201312), (201403, 201412), (201503, 201511), (201603, 201612), (201703, 201711), \
(201803, 201812), (201903, 201911)]
for (date_start, date_end) in year_list:
for date in range(date_start, date_end):
url = geturl(date, "LT")
st = cuturl(url)
ls = cutst(st)
sc = score(ls)
print(str(date)+" OK")
regist(sc, df)lotte.xlsx라는 파일의 첫 행에 YEAR, MONTH, DATE, DAY, WDL, R, ER, OP라고 입력한 뒤 저장하고 파일을 불러왔다.
각 해의 개막일, 최종전의 월이 다 달랐기 때문에 이건 직접 수작업을 할 수밖에 없었다.
완성하고 난 뒤인 지금에야 상관없지만, 중간에 오류가 나면 어디서 오류가 났는지 확인해야했다.
그래서 어디서 오류가 났는지 확인하기 위해 print(str(date)+" OK") 한 줄을 추가했다.
어디까지 정리가 되었는지 확인하기도 편했다.
이제 df에 테이블이 저장되었다. 이걸 이제 다시 lotte.xlsx에 보내준다.
df.to_excel(excel_file, index = False)
print("Saved!")index = False를 하면 엑셀 파일 첫 열에 0, 1, ... 의 인덱스는 저장되지 않는다.
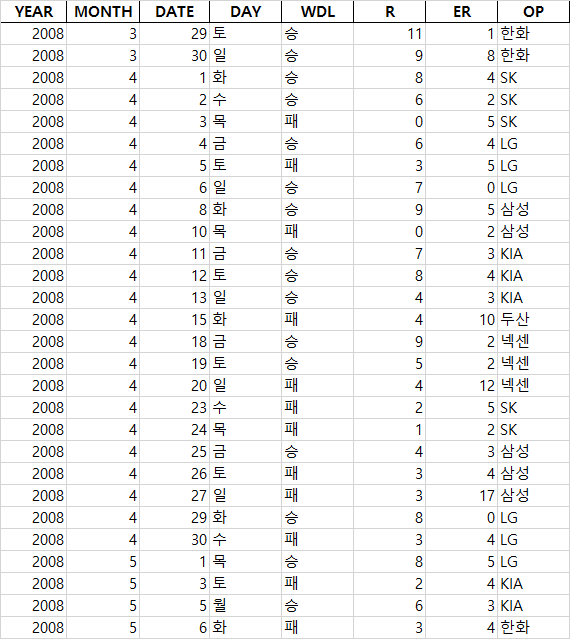
모든 데이터가 저장되었다!
다만 나는 가을야구 경기는 제외하고 싶었다. 그래서 엑셀 파일로부터 가을야구 데이터를 수작업으로 제외했다.
이제 남은 것은 머신러닝으로 예측해보는 것뿐이다!
* 전체 코드를 올립니다.
더보기
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
import os
from numpy import NaN
# url 가져오기
def geturl(date, teamname):
(year, month) = ym(date)
url = "https://sports.news.naver.com/kbaseball/schedule/index.nhn?&month="+str(month)+"&year="+str(year)+"&teamCode="+teamname
return url
# 날짜 자르기
def ym(date):
year = str(date)[:4]
month = str(date)[-2:]
return (year, month)
# 앞뒤 간편하게 자르기
def cuturl(url):
req = urllib.request.Request(url)
html = urllib.request.urlopen(req).read()
soup = BeautifulSoup(html, "lxml")
st = soup.get_text()
cut1 = st.find("알림받기")
cut2 = st.find("야구 홈으로")
st = st[cut1+4:cut2]
st = st.strip()
return st
# 각 날짜별로 점수 나누기
def cutst(st):
teamlist = ["SK ", "SK\n", "삼성", "LG", "롯데", "KIA", "한화", "넥센", "키움", "KT", "NC", "두산", "kt"]
tmp = []
while ("SK "in st) or ("SK\n" in st) or ("삼성" in st) or ("LG" in st) or ("롯데" in st) or ("KIA" in st) \
or ("한화" in st) or ("넥센" in st) or ("키움" in st) or ("KT" in st) or ("kt" in st) \
or ("NC" in st) or ("두산" in st) :
tmp2 = {}
tmp3 = []
for team in teamlist:
pos = st.find(team)
if pos == -1 :
continue
else :
tmp2[team] = pos
for k, v in tmp2.items():
tmp3.append((v, k))
tmp3 = sorted(tmp3)
if len(tmp3) == 0 :
break
pos1 = tmp3[0][0]
pos2 = tmp3[1][0]
st1 = st[:pos1].strip()
st2 = st[pos1:pos2+4].strip()
st1 = finddate(st1)
pos3 = st2.find("SKY")
if pos3 > 0 :
st2 = st2[pos3+10:].strip()
tmp.append((st1, st2))
st = st[pos2+3:].strip()
sky = st.find("SKY")
if (sky > 0 ) and (sky < 30):
st = st[sky+10:].strip()
return tmp
# string에서 날짜 찾기
def finddate(st):
pos1 = st.find("없습니다")
pos2 = st.find("V2")
pos3 = st.find("2TV")
if (pos1 >= 0) or (pos2 >= 0) or (pos3 >= 0):
pos = max(pos1, pos2, pos3)
st = st[pos+5:].strip()
return finddate(st)
try :
if len(st) == 0 :
return st
x = int(st[0])
return st
except :
st = st[1:]
return finddate(st)
# 날짜/요일/승무패/득점/실점/상대팀으로 정리하기
def score(ls):
tmp = []
for datestring, teamscore in ls :
pos0 = datestring.find(".")
pos1 = datestring.find("(")
pos2 = datestring.find(")")
month = datestring[:pos0].strip()
date = datestring[pos0+1:pos1].strip()
day = datestring[pos1+1:pos2].strip()
try :
month = int(month)
date = int(date)
except :
month = tmp[-1][0]
date = tmp[-1][1]
day = tmp[-1][2]
if "VS" in teamscore:
continue
else :
team1 = teamscore[:3].strip()
team2 = teamscore[-3:].strip()
pos4 = teamscore.find(":")
score1 = teamscore[3:pos4].strip()
score2 = teamscore[pos4+1:-3].strip()
score1 = int(score1)
score2 = int(score2)
if team1 == "롯데":
r = score1
er = score2
op = team2
else :
r = score2
er = score1
op = team1
if r > er :
wdl = "승"
elif r < er :
wdl = "패"
else :
wdl = "무"
tmp.append((month, date, day, wdl, r, er, op))
return tmp
def regist(sc, df):
for (month, date, day, wdl, r, er, op) in sc:
l = len(df["DATE"])
df.loc[l] = [int(str(date_start)[:4]), month, date, day, wdl, r, er, op]
base_dir = 'C:/Users/Username/Desktop'
excel_file = "lotte.xlsx"
excel_dir = os.path.join(base_dir, excel_file)
df = pd.read_excel(excel_dir, encoding="EUC_KR")
year_list = [(200803, 200811), (200904, 200911), (201003, 201011), (201104, 201111), (201204, 201212), \
(201303, 201312), (201403, 201412), (201503, 201511), (201603, 201612), (201703, 201711), \
(201803, 201812), (201903, 201911)]
for (date_start, date_end) in year_list:
for date in range(date_start, date_end):
url = geturl(date, "LT")
st = cuturl(url)
ls = cutst(st)
sc = score(ls)
print(str(date)+" OK")
regist(sc, df)
df.to_excel(excel_file, index = False)
print("Saved!")
(다음 글에 이어서)
728x90
반응형
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| 머신러닝과 기상 데이터를 이용해 홈런 갯수 예측해보기 (1) 소스 가져오기 (0) | 2020.05.10 |
|---|---|
| 머신러닝으로 야구 득/실점 예측해보기 (5) 머신러닝 (0) | 2020.05.05 |
| 머신러닝으로 야구 득/실점 예측해보기 (3) 스코어 뽑아내기 (0) | 2020.05.05 |
| 머신러닝으로 야구 득/실점 예측해보기 (2) string 정리하기 (0) | 2020.05.05 |
| 머신러닝으로 야구 득/실점 예측해보기 (1) 소스 가져오기 (0) | 2020.05.05 |


