pytorch 공부 (2) - ANN 구현하기
- 목차
2024.03.08 - [데이터 분석/딥러닝] - pytorch 공부 (1) - 기본 연산
FashionMNIST 데이터 불러오기
from torchvision import datasets, transforms
from torch.utils import data
train_loader = data.DataLoader(
datasets.FashionMNIST('dataset/', train=True, download=True, # 다운로드 경로
transform=transforms.Compose([ # 이미지를 텐서로 바꿔주는 코드
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
),
batch_size=32
)
test_loader = data.DataLoader(
datasets.FashionMNIST('dataset/', train=False, download=True, # 다운로드 경로
transform=transforms.Compose([ # 이미지를 텐서로 바꿔주는 코드
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
),
batch_size=32
)- `transform`: 이미지 데이터를 학습용 데이터로 변환
- `ToTensor()`: 이미지를 텐서로 변환
- `Normalize()`: 정규화
- `batch_size`: 배치 사이즈. 많은 데이터를 메모리에 한 번에 올릴 수 없기 때문에 데이터를 배치 사이즈만큼 불러와서 학습하고 다음에 다시 배치 사이즈만큼 데이터를 불러와서 학습을 반복한다.
데이터 확인(시각화)
import matplotlib.pyplot as plt
import numpy as np
import torch
images, labels = next(iter(train_loader))
torch_image = torch.squeeze(images[0]) # 1차원 축 제거
plt.imshow(torch_image.numpy(), 'gray')
plt.show()
ANN 구현하기
라이브러리 호출 및 디바이스 정의
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as f
torch.manual_seed(14) # 시드
use_cuda = torch.cuda.is_available()
device = torch.device('cuda' if use_cuda else 'cpu')
device # device(type='cuda')- `device`: GPU를 사용할 수 있는 환경일 경우 `cuda` 사용
ANN 모델 정의
# 모델 정의는 클래스 형태로 정의
class Ann(nn.Module):
def __init__(self):
super(Ann, self).__init__()
self.fc1 = nn.Linear(784, 256) # input layer, 784 = 28*28
self.fc2 = nn.Linear(256, 128) # hidden layer
self.fc3 = nn.Linear(128, 10) # output layer
def forward(self, x): # 정방향 연산 (입력->출력)
x = x.view(-1, 784) # 1차원으로 펼치기
x = f.relu(self.fc1(x)) # relu 활성화 함수
x = f.relu(self.fc2(x))
x = self.fc3(x)
return x- `class Ann(nn.Module)`: tensorflow와 달리 torch 모델은 클래스 형태로 정의
- `def forward(self, x)`: 정방향 연산 (입력으로 `x`를 넣고 출력은 layer를 통과한 `x`)
정보
데이터를 모델에 전달할 때 `model.forward(x)` 대신 `model(x)`를 사용할 수 있다. 이게 가능한 이유는 `nn.Module` 클래스의 `__call__(self, *input, **kwargs)` 함수에서 `self.forward(*input, **kwargs)`를 하고 있기 때문이다.
ANN 모델 학습
model = Ann().to(device) # 모델의 파라미터들을 지정한 장치의 메모리로 전달
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 학습하기 전 model이 train할 수 있도록 train mode로 변환
model.train()
data, target = images.to(device), labels.to(device) # 추출한 batch 데이터 1개를 device에 전달
optimizer.zero_grad() # 기울기 초기화 - 새로운 최적화 값을 찾기 위해 준비
output = model(data) # 모델에 데이터 전달(예측)
# output과 target의 오차 계산
# 오차에 최적화 알고리즘을 통해 가중치를 줄여나가는 함수
loss = f.cross_entropy(output, target)
loss.backward() # 기울기 계산
# 기울기를 가중치로 수정
optimizer.step()- `optimizer`: 모델 최적화 함수
- `SGD`: 확률적 경사 하강법
- `model.parameters()`: `model`의 파라미터를 최적화 하겠다는 의미
- `lr`: learning rate
- `model.train()`: 모델의 파라미터가 업데이트될 수 있도록 train mode로 변환
- `optimizer.zero_grad()`: 기울기 초기화. 새로운 최적화 값을 찾기 위한 준비
- `loss.backward()`: 기울기 계산
- `optimizer.step()`: 기울기를 가중치로 수정
ANN 모델 반복 학습
EPOCHS = 10
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1, EPOCHS+1):
model.train()
# 학습 데이터를 배치 사이즈만큼 반복
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = f.cross_entropy(output, target)
loss.backward()
optimizer.step()
print(f'Train Epoch: {epoch}\tLoss:{loss.item():.6f}')- `EPOCHS`: 학습 반복 횟수

성능 평가
train_history = []
test_history = []
for epoch in range(1, EPOCHS+1):
model.train()
# 학습 데이터를 배치 사이즈만큼 반복
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = f.cross_entropy(output, target)
loss.backward()
optimizer.step()
print(f'Train Epoch: {epoch}\tLoss:{loss.item():.6f}')
train_history.append(loss.item())
model.eval() # 검증 모드
test_loss = 0 # 테스트 데이터 오차
correct = 0 # 정답 수
with torch.no_grad(): # 평가 때는 기울기 계산 필요 없음
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += f.cross_entropy(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True) # dim=1: 차원, keepdim=True: 차원 유지
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_history.append(test_loss)
print(f'Test set: Average Loss: {test_loss:.4f}, Accuracy: {correct/len(test_loader.dataset)*100:.0f}%\n')- `model.eval()`: 검증 모드로 파라미터 업데이트를 하지 않음
- `with torch.no_grad()`: 파라미터를 업데이트하지 않기 때문에 기울기 계산도 필요 없음
- `f.cross_entropy(output, target, reduction='sum')`: 테스트 데이터의 loss 계산
- `reduction='sum'`: `cross_entropy` 함수를 거쳐서 나오면 배치 사이즈 크기의 loss tensor가 만들어지는데, `reduction='sum'`을 통해 배치 사이즈의 loss를 합친다. 기본값은 `mean`으로 보통 학습할 때 사용한다.
- 그래서 학습할 때 출력하는 loss는 전체 데이터가 아닌 마지막 배치 데이터의 loss다.
- `pred = output.argmax(dim=1, keepdim=True)`: 1차원(가로 방향)의 데이터 중 가장 큰 데이터의 index를 반환
- `pred.eq(target.view_as(pred)).sum()`: 실제와 예측 라벨이 같은 데이터의 개수 계산

import matplotlib.pyplot as plt
plt.plot(train_history, color='tab:green')
plt.plot(test_history, color='tab:red')
plt.show()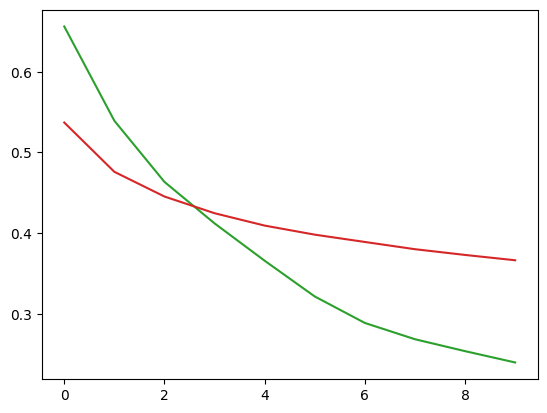
성능 개선
과적합 해결 방법
- 데이터 정규화
- Normalize 옵션 사용
- 평균과 표준편차 값을 지정해서 정규화
- Dropout
- 신경망의 일부를 사용하지 않음
- 개별 뉴런의 연산 결과에 가중치가 고정되는 현상 방지
- 데이터 더 모으기
- 데이터를 일부 변형하여 개수 증가
데이터 다시 불러오기
from torch.utils import data
train_loader = data.DataLoader(
datasets.FashionMNIST('dataset/', train=True, download=True, # 다운로드 경로
transform=transforms.Compose([ # 이미지를 텐서로 바꿔주는 코드
transforms.RandomHorizontalFlip(), # 랜덤으로 좌우 변경하여 데이터 수 2배 증가
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
),
batch_size=32
)
# 테스트 데이터는 그대로 사용
test_loader = data.DataLoader(
datasets.FashionMNIST('dataset/', train=False, download=True, # 다운로드 경로
transform=transforms.Compose([ # 이미지를 텐서로 바꿔주는 코드
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
),
batch_size=32
)- `transforms.RandomHorizontalFlip()`: 랜덤으로 좌우를 변경하여 데이터 수를 2배 증가시킴
모델 재정의
class Ann(nn.Module):
def __init__(self, dropout=0.2):
super(Ann, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 10)
self.dropout = dropout
def forward(self, x):
x = x.view(-1, 784)
x = f.relu(self.fc1(x))
x = f.relu(self.fc2(x))
x = f.dropout(x, training=self.training, p=self.dropout) # dropout 추가
x = self.fc3(x)
return x- `f.dropout()`: dropout 함수
- `p`: dropout 비율
모델 재학습
`EPOCHS=30`으로 변경하여 학습


'데이터 분석 > 딥러닝' 카테고리의 다른 글
| torch와 tensorflow를 CNN 코드로 비교하기 (0) | 2024.03.21 |
|---|---|
| pytorch 공부 (3) - RNN 구현하기 (0) | 2024.03.19 |
| torch, tensorflow를 같은 가상환경에 설치하기 (0) | 2024.03.13 |
| pytorch 공부 (3) - CNN 구현하기 (0) | 2024.03.12 |
| pytorch 공부 (1) - 기본 연산 (0) | 2024.03.08 |


