시계열 이상탐지 (4) - 딥러닝의 시대
- 목차
이하 내용은 MIT - Data to AI Lab에서 작성한 글을 일부 번역 및 요약한 것입니다.
Part 1
Time series anomaly detection — in the era of deep learning
시계열 이상 탐지란
시계열 데이터: 시간을 인덱스로 가지는 점들의 집합

이상치(anomaly): 가끔 등장하는 시계열 내에 속하지 않는 데이터(정상 패턴과 다른 패턴)

이상치의 종류
- 점 이상치(Point anomalies): 낮은 밀도 영역에 속하는 단일 값. 많이 모여있으면 집합 이상치(collective anomalies)라고 불림
- 맥락적 이상치(Contextual anomalies): 낮은 밀도 영역에 속하지는 않지만 지역적으로 이상한 값들로, 시작 시간과 끝 시간으로 이루어진 시간 간격으로 정의된다.
 점 이상치 |
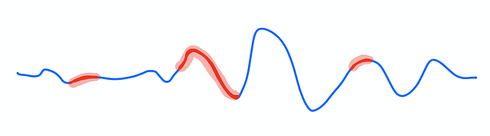 맥락적 이상치 |
이상 탐지를 하는 전통적 방법
- Static thresholding: 특정 범위를 벗어난 값이 나오면 알림을 주는 방법. 그러나 문맥적 이상치는 잡아내지 못한다.
- 통계적 모델(ARIMA 등), 확률 모델(HMAD), 클러스터링 기반(CBLOF), 근접이웃 기반(K-NN), 밀도 기반(LOF) 등이 있음
- 최근엔 딥러닝 모델로 이상 탐지 시도를 하고 있는데, 대표적으로 RNN이 있다. RNN으로 값을 “예측”한 후 예측값과 실제값의 차이로 이상치를 정하는 방식이다.
머신 러닝(딥러닝) 모델의 기본적인 원리:
1. 머신 러닝은 데이터의 패턴을 학습한다.
2. 학습한 모델로 다른 시계열 데이터를 만들어낸다.
3. 모델이 만든 데이터와 실제 데이터를 비교한다.
4. 불일치를 이용하여 이상치를 추출한다.

시계열 이상 탐지가 어려운 이유
(1) Non-stationary: 통계적 특성이 시간이 지남에 따라 변할 수 있음 (5년 전 이상 패턴이 현재는 정상 패턴)
(2) Complex patterns: Trend, seasonality, random과 같은 복잡한 패턴이 있을 수 있음
(3) Large data volumes: 관측값이 매우 많아 계산 비용이 클 수 있음
(4) Multiple types of outliers: 점 이상치, 문맥적 이상치 등 여러 종류의 이상치가 있으며 각각에 따라 다른 감지 기법을 필요로 한다.
(5) Lack of universal definition: 이상치에 대한 보편적인 정의가 없음
Part 2
Time series anomaly detection — in the era of deep learning
적대적 생성 네트워크를 이용한 시계열 이상 탐지
적대적 생성 네트워크(GAN; generative adversarial networks): 신경망인 생성자(G; generator)가 랜덤 노이즈를 이용하여 가짜 이미지를 생성하고 판별자(D; discriminator)를 속인다. 또 역시 신경망인 판별자는 가짜와 진짜를 구분한다. 생성자와 판별자가 서로 경쟁하게 되고 마침내 진짜 같은 가짜 이미지가 만들어진다.
시계열에서도 같은 접근법이 사용되는데, G가 데이터의 패턴을 학습하여 시계열 데이터를 만들어내고 진짜와의 차이로 인한 오차를 계산한다. 이 오차로 이상치를 판별하게 된다.
전처리
GAN에 데이터를 넣기 이전에 성능을 높이기 위한 전처리가 필요하다.
- 데이터의 시간 간격을 동일하게 맞춰준다.
- 결측치를 채워준다.
- 데이터를 -1~1로 정규화한다.
- 슬라이딩 윈도우를 통해 훈련 데이터를 생성한다. (윈도우 사이즈에 따라 결과가 달라진다.)

모델링
학습 - 재구성 기반(reconstruction-based) 이상 탐지의 주된 아이디어는 이전에 본 것과 유사한 패턴을 생성(구성)할 수 있는 모델을 학습하는 것

재구성 - GAN 학습이 끝나면 인코더(E)와 생성자(G)를 이용하여 데이터를 재구성한다.

한 데이터 포인트에 대해 윈도우 사이즈 수만큼 데이터가 재구축되는데, 그 값들을 aggregate하여 최종 재구축 데이터를 생성한다. (이 때, aggregate하는 방법은 중앙값을 선정하는 것)

후처리
재구축된 데이터와 실제 데이터를 이용하여 이상치를 찾는다.
- 이상 점수를 계산한다.
- 점수에 따라 이상치 구간을 찾아낸다.

- MAE, 면적 차이 혹은 DTW 등으로 점수를 계산한다.

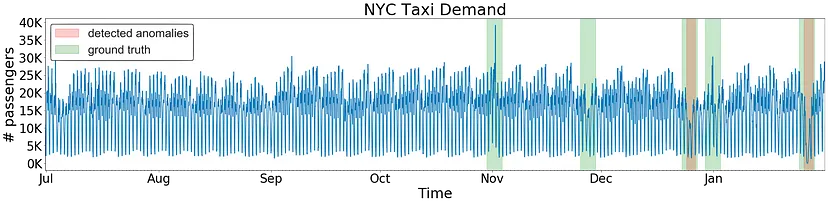

Part 3
Time series anomaly detection — in the era of deep learning
Ground Truth가 있을 때 이상 탐지 모델을 평가하는 방법에 대한 소개글.
'데이터 분석 > 이상탐지' 카테고리의 다른 글
| 시계열 이상탐지 (3) - VAE, TadGAN (0) | 2024.03.22 |
|---|---|
| 시계열 이상탐지 (2) - LSTM-DT, LSTM-AE, AER (0) | 2024.03.20 |
| 시계열 이상탐지 (1) 배경 지식 (0) | 2024.03.15 |
| 이상탐지 알고리즘 - ECOD 논문 읽기 (0) | 2024.02.20 |



