[AWS Summit Seoul 2024] LLM의 프롬프트 엔지니어링
- 목차
후기
선 후기 - 후 정리를 하자면, 웬만한 내용들은 나를 포함하여 LLM에 관심이 있는 사람이라면 이미 다 알고 있거나 실제로 적용 중인 내용들이었다. 다만 나는 주로 OpenAI의 API를 써왔고 AWS의 내용은 Bedrock의 Claude 모델에 대한 내용이었기 때문에 모델에 의한 차이는 존재했다. 지금은 압도적인 성능을 가진 GPT-4o가 나오면서 OpenAI API를 사용하고 있지만 나중에는 결국 모델의 성능은 비슷하지만 요금에서 차이가 나거나, 편의성 면에서 AWS의 모델이 더 우수할 가능성이 있기 때문에 AWS에서 들은 세션 내용을 정리해본다.
내용 정리
1. Persona를 적용하라.
OpenAI API로 보자면 [System] 메시지를 적용하는 것이다. OpenAI에서는 기본값으로 "You are an assistant"로 되어있을텐데 해당 메시지에서 역할을 주어주는 것이다.
예) 너는 해당 문서에 대한 답을 하는 챗봇이야. // 너는 IT 지식이 없는 사람에게 LLM에 대해 설명해주는 도우미야.
2. One-Shot과 Few-Shot을 이용하라.
쉽게 말하면 예시를 주고 답하게 시키라는 것이다. One-Shot은 예시 하나만 주는 거고, Few-Shot은 예시 여러 개를 주는 것이다.
예) "10+10은?" 이라는 질문에 "덧셈이다."라는 답을 받고 싶다면 "1+1은 덧셈이다. 1-1은 뺄셈이다. 1*1은 곱셈이다. 1/1은 나눗셈이다." 다음에 "그러면 10+10은?"이라는 질문을 하면 된다.
이와 관련해서는 논문이나 관련 글도 많으니 관심이 있다면 찾아보도록 하자.
3. CoT(Chain of Thought)를 이용하라.
LLM을 스스로 묻고 답하게 하는 방식으로, 정확한 답을 얻도록 단계별로 진행시키는 방법이다. 영어 번역 그대로 "생각의 연쇄"로, 질문에 대해 중간 단계를 추론한 후 문제 해결에 대한 디테일을 제공하는 것이다. 예를 보면 이해가 쉬울 수 있다.
예) "2, 3, 4, 6, 8, 11 중에서 홀수의 합을 알려줘"라는 질문을 했을 때, "답은 14입니다."가 일반적인 답변이라면, CoT를 사용하면 "먼저 홀수를 찾아야 합니다. 홀수는 3, 11입니다. 이제 이 둘을 합하여 답을 얻습니다. 답은 14입니다."로 나온다.

사실 이것도 오래된 기법 중 하나이기 때문에 요즘 나오는 모델들은 이런 간단한 문제에 대해서는 프롬프트 없이도 CoT를 한다. 다만 논리적으로 긴 문제는 프롬프트를 주지 않으면 잘 못 하는 경우가 있으므로 주의해야 한다.
4. RAG(Retrieval-Augmented Generation)를 사용하라.
이 기법도 실제로 많이 쓰이는 것으로, 대용량의 문서를 벡터화하고 사용자의 질문과 가장 유사한 벡터를 찾은 뒤, 필요한 부분만 따로 프롬프트에 넣고 답을 얻는 방법이다. LLM은 학습에 사용된 데이터에 대해서만 답을 할 수 있기 때문에, 특정 분야나 회사의 정보 등은 답을 못하는 경우가 많다. 이를 극복하기 위해서는 프롬프트에 해당 정보를 넣어줘야 하는데, 그렇게 하면 토큰 수가 늘어나 제한이 생긴다. 그래서 이 RAG 방법을 사용하여 문서에서 필요한 부분만 추출해서 프롬프트에 넣어준다. 요즘에는 RAG를 위한 VectorDB가 다양하게 나오고 있다. RAG를 하는 방법은 `langchain` 같은 툴을 써도 되고, 또는 AWS Bedrock에서는 콘솔에서 해당 기능을 지원한다.
5. 많은 실험이 필요하다.
AWS에서 프롬프트의 구성요소를 다음과 같이 정리해주셨다.
1. "\n\nUser:"
2. 작업 컨텍스트
3. 어조 컨텍스트
4. 처리할 배경 데이터
5. 세부 작업 설명 및 규칙
6. 예시
7. 즉시 처리할 데이터
8. 즉각적인 작업 설명 또는 요청
9. 단계별로 생각하기 / 심호흡하기
10. 출력 양식
11. "\n\nAssistant:"
구성요소가 많기 때문에 처음에는 전부 넣고 해보고 나중에 세분화하던가 빼던가 하면서 프롬프트 엔지니어링을 많이 해봐야 한다고 했다. 맞말인게 사실 저걸 다 넣고 해도 제대로 답하는 경우가 없을 때가 무조건 생긴다. 출력 양식을 지정해줬는데 안 지킨다거나, 예시 코드를 줬는데 그대로 안 따르고 마음대로 작성한다거나... temperature 같은 것도 만져주면서 많은 실험을 해보아야 한다.
6. 설계 방법
테스트 케이스 작성 → 프롬프트 초안 작성 → 프롬프트 검징 및 수정 → 프롬프트 공유
7. 명확하고 직접적으로 표현하기
8. 예제 사용하기
One-shot, Few-shot과 겹치는 내용이긴 한데, 예제가 늘어날수록 답변이 정확해진다. 다만 토큰이 늘어나고 답변이 나오는 시간은 더 길어진다는 점은 유의해야한다.
9. 생각할 시간을 제공하기
CoT와 비슷한 내용이긴 한데, 아래와 같이 스스로 생각할 시간을 주거나 아니면 스스로 묻고 답하도록 LLM을 여러 번 거치도록 한다.
예) [thinking...] ~~~
[answer...] ~~~
의 형식으로 답하도록 하기
또는 LLM을 여러 번 거치도록 한다.
예) ( [thinking...] ~~~ ) 의 결과를 LLM에 전달하여 그에 맞는 답을 얻기.
이를 잘 활용한 기업으로 아모레퍼시픽이 있다.
전처리한 리뷰 원문을 LLM에 전달하여 요약하도록 하고, 그 요약이 잘 나왔는지 LLM에게 전달하여 평가하도록 하고, 요약과 평가를 함께 다시 LLM에 전달하여 재요약하도록 하는 것이다.
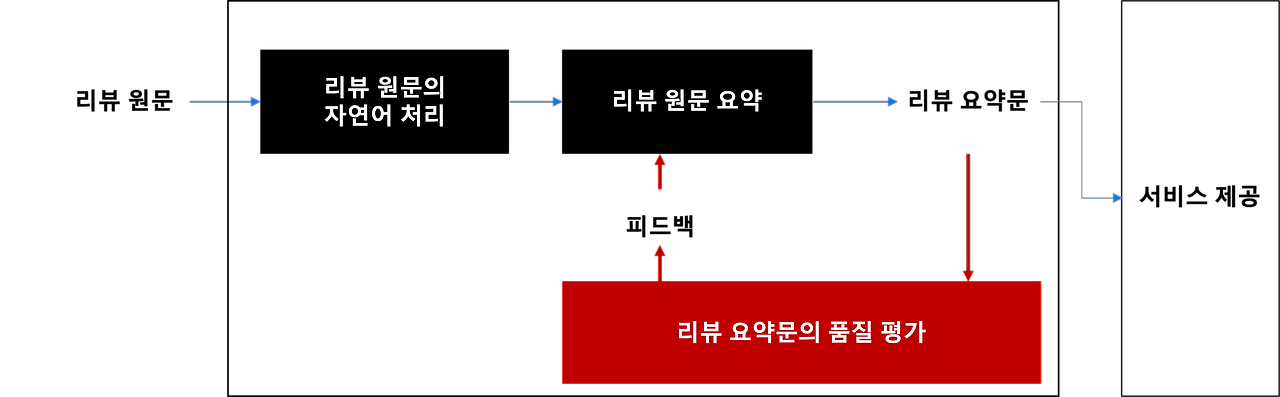
이렇게 하면 좀 더 좋은 요약문이 나올 거라 충분히 예상할 수 있다. (대신 그만큼 요금이 많이 나갈 것이다.)
10. XML 태그를 사용하기 (Claude 모델 한정)
Claude가 XML 태그로 학습했다고 했던가... 그래서 저걸 넣으면 더 잘 인식하고 답한다고 한다.
예를 들어 이메일 내용을 요약해달라는 요청을 할 때, 이메일 부분을 <email> </email>로 감싸주면 더 잘 대답을 한다는 것이다.
11. 출력 형식을 지정할 때, Claude를 대신해서 말을 시작하기
이건 Chat 모드 말고 Completion 모드 한정이다. 먼저 간단하게 Chat 모드와 Completion 모드를 설명하고 넘어가자면
- Chat 모드: User와 Assistant의 메시지가 json으로 파싱되어 나오는 구조.
messages = [
{
"role": "user",
"content": [{
"type": "text",
"text": "안녕. 너는 누구니?"
}],
},
]
answer = bot.ask(messages)
print(answer)
"""
{
"role": "assistant",
"content": [{
"type": "text",
"text": "안녕하세요. 저는 Claude 3입니다."
}],
}
"""- Completion 모드: 유저가 입력한 문장을 LLM이 완성시키는 구조. 이 모드에서 대화를 하려면 앞서 5번의 1, 11번인 `"\n\nUser: ~~~ \n\nAssistant:"`로 프롬프트를 주게 된다. (뇌피셜이지만 GPT시리즈도 포함하여 LLM들 모두 Completion이 기본인데 프롬프트 엔지니어링과 파싱을 통해서 Chat 모드를 만든 것 같다.)
prompt = "\n\nUser: 안녕. 너는 누구니?\n\nAssistant: "
answer = bot.ask(prompt)
print(answer) # 안녕하세요. 저는 Cluade 3입니다.
그래서 결국 하고자 하는 말은 만약 LLM이 json 형태로 출력을 하도록 원한다면 프롬프트의 마지막을 `\n\nAssistant: {`로 하여 강제로 json 형태로 답하도록 한다는 것이다.
12. 환각 대처하기
- 모르면 모른다고 대답하도록 하기
- 확실한 경우에만 대답하도록 하기
- 인용문이 있다면 추적할 수 있도록 하기
고급 기법
1. 프롬프트 체이닝
복잡한 작업을 여러 단계로 나누어서 처리하는 기법이라고 한다. Claude를 만든 Anthropic에서 주로 소개하고 있다.
2. 긴 프롬프트 입력 시...
GPT-4도 그렇고, Claude 모델도 3부터 긴 프롬프트 입력이 가능해지면서 이런 기법이 나온 것 같다.
- 긴 문서 Q&A의 경우, 문서 뒤 프롬프트 끝에 질문하기
- 긴 형식의 입력 데이터는 반드시 XML 태그 넣기
- 질문과 관련된 인용문을 찾은 다음 관련 인용문을 찾은 경우에만 답하도록 지시하기
- 나중에 질문이 있을 것이므로 주의 깊게 읽어보라고 하기
3. Agents 이용
API와 연결해서 쓰는 건데, Bedrock에서는 이 기능을 지원한다. 근데 프롬프트 엔지니어링과는 관계가 없는듯 싶지만 아는 내용을 적어보자면...
API와 그에 들어가는 파라미터, 리턴값 등이 적힌 문서를 미리 만들어두면, 질문을 받았을 때 스스로 API에 요청할 것인지, 어느 API에 요청할 것인지 선택한 후 그 리턴값을 받아와서 답을 만들게 된다.
예) "지금 날씨가 어때?" 라는 질문을 받으면 미리 작성된 날씨와 관련된 API를 호출하고 현재 날씨를 리턴을 받아 답을 하게 된다.
4. RAG
문서와 관련 없는 질문의 경우 RAG를 하면 답변 성능이 떨어진다고 한다. 또, 여러 주제의 문서를 DB에 담아놓고 답하도록 하면 답이 혼재되어 정확한 답을 얻을 수 없게 된다. 이를 방지하기 위해서는 질문의 종류에 따라 바라보는 VectorDB를 달리 보도록 해야 한다. AWS 세션에서는 이걸 수행하는 방법에 대해 자세히 내용을 말해주지 않았지만 Agents와 비슷한 구조로 만들면 될 것 같다.
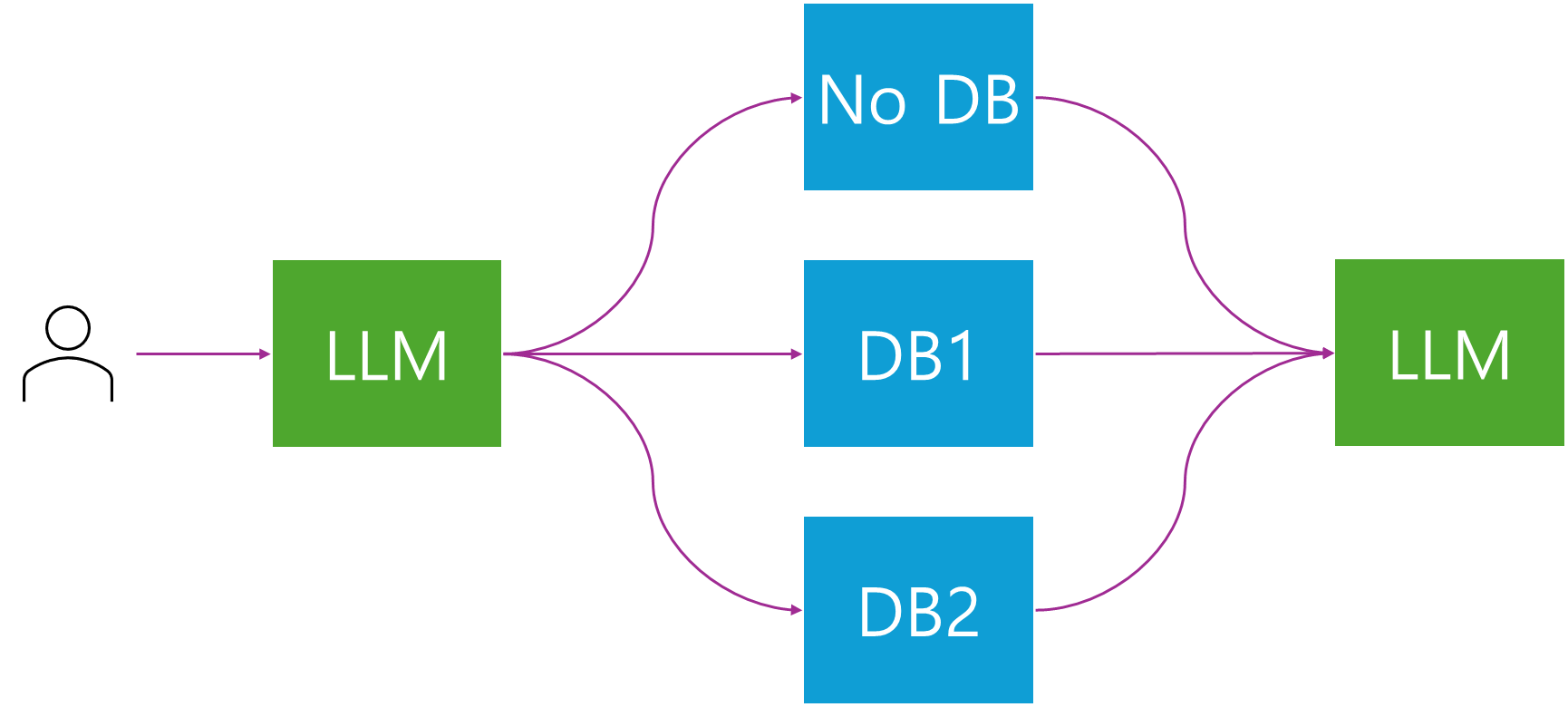
유저가 질문을 던지면 앞 LLM은 RAG 하지 않고 답할지, DB를 본다고 하면 1, 2중에 어떤 걸 볼 것인지 선택하도록 한 뒤 그에 맞춰 RAG를 수행하고 LLM에게 답변을 받는 프로세스일 것 같다.
이렇게 보면 Agent와 크게 다른 게 없는 것 같다. 각 DB를 바라보는 API를 만들어놓고 Agent한테 알아서 선택하라고 하면 되니까...
확실히 LLM이 나오고 편해진 게 원래 이런 걸 하려면 분류 모델 만들어서 해야하는데 이젠 LLM이 분류까지 알아서 해주니까 뭐, 할 게 없다.
'AWS' 카테고리의 다른 글
| AWS Lambda와 API Gateway를 통해 입력 받은 이미지 처리하기 (0) | 2024.05.02 |
|---|---|
| AWS Lambda만을 이용해서 날씨알림봇 만들기 (0) | 2024.04.22 |
| AWS Lambda, API Gateway로 대화형 질답봇 만들기 (Feat. 야구) (0) | 2024.04.02 |
| AWS Lambda와 selenium을 이용해서 날씨알림봇 만들기 (0) | 2024.03.07 |
| AWS Cloud9과 ECR을 이용하여 Lambda Container 배포하기 (0) | 2024.02.23 |



