AutoML, Autogluon vs mljar-supervised
- 목차
AutoML?
Auto+ML로 머신러닝에 필요한 데이터 전처리, 모델 튜닝, 학습 등 여러 수행사항들을 쉽고 간단하게 코드 몇 줄을 통해 자동으로 알아서 해주는 도구이다. 간단하기만 할 뿐만 아니라 성능도 잘 나온다.
AutoML의 필요성
- 기존 방식: 데이터를 가공(결측치 처리 등)하여 어떤 알고리즘을 사용할지 선택하고 필요 시 하이퍼파라미터를 튜닝하며 학습 및 평가를 진행한다. 만약 결과가 좋지 않으면 다른 알고리즘으로 새롭게 테스트하는 과정을 무한 반복 …
이걸 코드로 옮겨 적으면 수십~수백 줄에 달하는 노동 집약적인 과정이며 시간 소요도 크다.
- 하지만 automl 패키지를 사용하면 `model.fit()` 몇 줄로 가공부터 학습까지 모든 과정이 끝난다.

- 따라서 데이터 분석가/사이언티스트가 다른 과정에 시간을 더 쏟을 여유가 생긴다.
- 자주 언급되고 사용되는 automl 툴에는 크게 AWS에서 만든 `autogluon`과 MLJAR에서 만든 `mljar-supervised`가 있다.
실제 코드(Autogluon)
from autogluon.tabular import TabularPredictor
label = 'target' # 예측할 Y 컬럼명
predictor = TabularPredictor(path='autogluon', label=label).fit(train_data=train_data)
실제 코드(mljar)
from supervised import AutoML
X = train_data[features]
y = train_data[label]
automl = AutoML(results_path="mljar", eval_metric='accuracy')
automl.fit(X, y)
Autogluon
- AWS에서 개발한 automl 툴 (autogluon)
- 테이블 형식 데이터 분류/회귀 모델을 비롯하여 텍스트 분류, 이미지 분류/객체 탐색, 시계열 예측 모델 생성 등을 지원
- AWS에서 개발, 지원하는 패키지이기 때문에 Sagemaker를 통해 배포하기 용이하다. (전용 컨테이너를 제공한다.)
Autogluon의 학습 방식
데이터 전처리
- 회귀/분류 모델 결정
- 범주형 변수를 원-핫 인코딩 또는 임베딩 처리, 결측치는 모델에 따라 다르긴 하지만 중앙값으로 채우고, 동일한 값만 있는 컬럼 제거, 모두 다른 값만 있는 컬럼 제거 등 표준화 작업을 거친다.
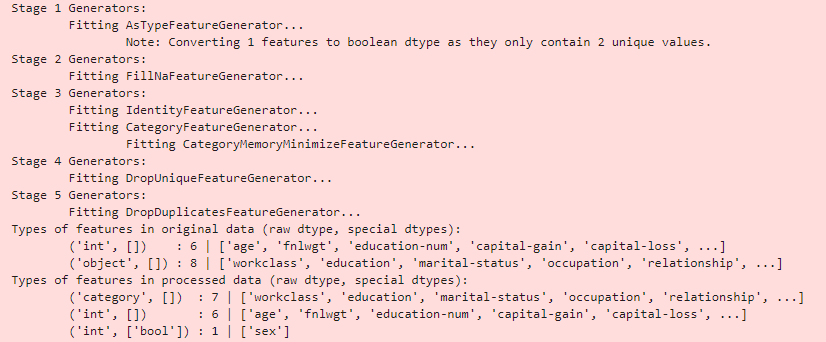
학습 및 튜닝
- 알고리즘 종류: 랜덤포레스트, XGBoost, Light GBM, KNN, ExtraTrees, CatBoost, DNN 및 앙상블, 스태킹 모델
- 홀드아웃 비율에 따라 train / validation 세트로 나눠 학습 및 평가를 진행
- `presets` 파라미터를 통해 성능 위주/적당한 성능과 추론 시간/빠른 추론 시간을 선택할 수 있다.
| Presets | Model Quality | Use Cases | Fit Time (Ideal) | Inference Time (Relative to medium_quality) | Disk Usage |
| best_quality | State-of-the-art (SOTA), much better than high_quality | When accuracy is what matters | 16x+ | 32x+ | 16x+ |
| high_quality | Better than good_quality | When a very powerful, portable solution with fast inference is required: Large-scale batch inference | 16x | 4x | 2x |
| good_quality | Significantly better than medium_quality | When a powerful, highly portable solution with very fast inference is required: Billion-scale batch inference, sub-100ms online-inference, edge-devices | 16x | 2x | 0.1x |
| medium_quality | Competitive with other top AutoML Frameworks | Initial prototyping, establishing a performance baseline | 1x | 1x | 1x |
- `best_quality`는 성능은 좋지만 학습 및 추론 시간이 오래 걸려 실시간 예측이 필요한 서비스에는 맞지 않는다.
- `medium_quality`는 추론 속도는 빠르지만 성능 면에서 뒤처지는 단점이 있다.
- 필요 시 하이퍼파라미터 튜닝 옵션을 줄 수 있다.
모델 평가
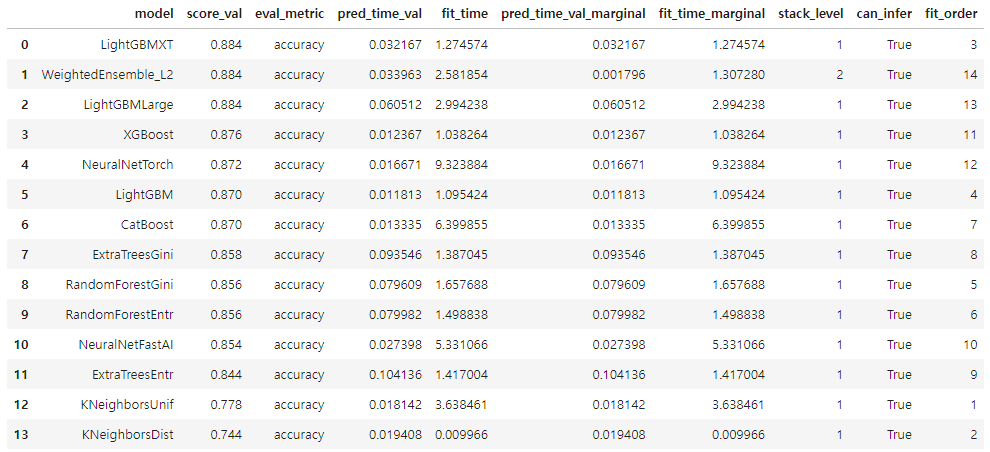
- `predictor.leaderboard()`를 통해 모델별 평가, 추론 시간 등을 확인할 수 있다.
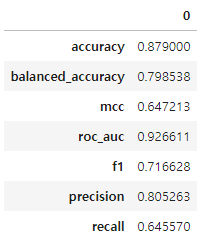
- `predictor.evaluate(test_data)`를 통해 테스트 데이터에 대한 평가 지표들을 확인할 수 있다.
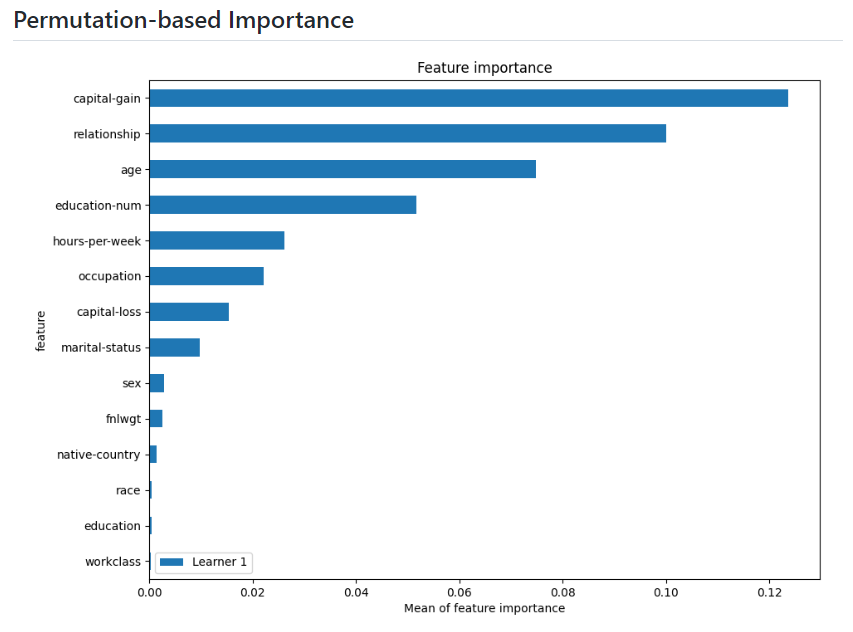
- `predictor.feature_importance(data=test_data)`를 통해 Permutation Importance를 확인할 수 있다.
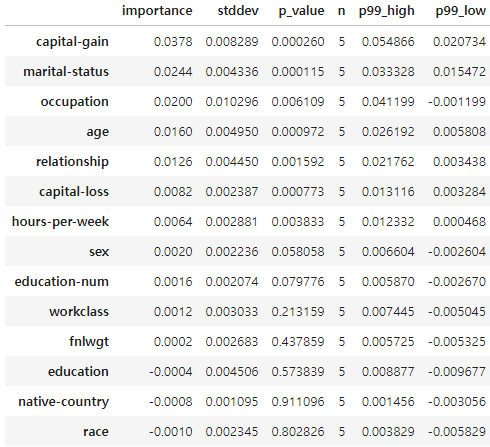
참고) Permuation Importance 관련하여 정리한 github
mljar-supervised
- MLJAR 팀에서 만든 automl 툴 (mljar-supervised)
- Feature Engineering을 해주며 결과에 대한 분석 및 시각화까지 해준다는 장점이 있다.
mljar의 학습 방식
- `Baseline`을 두고 ml로 예측이 가능한 데이터인 지를 확인
- (무지성으로) 예측을 했을 때 결과를 baseline으로 둠
- 예) 비가 오는지를 예측할 때 비 오는 날의 데이터가 20%인 경우, 예측 정확도 80%가 baseline
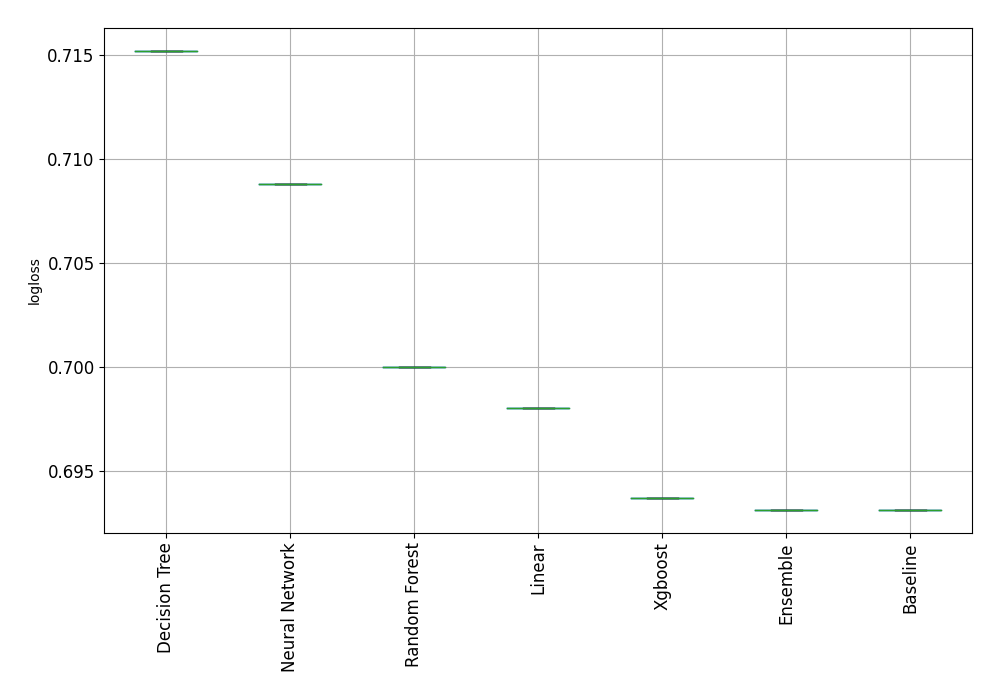
아래 랜덤 데이터로 학습하여 모델을 생성한 예제를 보자. logloss는 작을수록 좋은 모델인데, `Baseline`의 성능이 가장 뛰어나다. 이 말은 ML로 예측이 되지 않는 데이터로 가정 수립과 데이터 수집부터 다시 수행해야 한다는 의미이다.
- `autogluon`의 `presets` 파라미터와 비슷하게 `mode` 파라미터가 있다. Explain(데이터 이해), Perform(배포를 위한 학습), Compete(성능 위주)를 선택할 수 있다.
- 알고리즘 종류: 랜덤 포레스트, ExtraTrees, XGBoost, LightGBM, CatBoost, KNN, DNN 및 앙상블 모델
Explain 모드

- 각 알고리즘들로 학습 및 앙상블 모델 생성
- 학습 당시 지정한 경로에 학습 결과 문서(`README.md`)를 저장

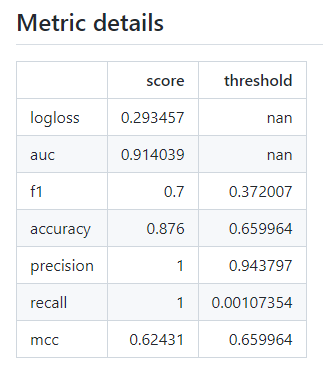
- 각 알고리즘을 선택해서 들어가면 어떤 하이퍼 파라미터로 학습 되었는지, 평가 결과는 어떠한지, 중요 feature가 무엇인지, 검증 당시 틀리게 예측한 데이터가 어떤 feature 때문에 그랬는지를 설명해주는 그래프를 볼 수 있다. → autogluon에서는 직접 해야하는 작업을 대신 해주는 장점이 있다.


Perform 모드
1차 학습
- 기본 알고리즘들로 학습을 진행
- 하이퍼 파라미터 튜닝 (랜덤 서치)
Feature Engineering - 1 (Golden Features)

- 모든 feature 중 한 쌍 골라 가능한 모든 연산에 대한 새로운 feature를 만든다. (덧셈/뺄셈/곱셈/나눗셈)
- 각 feature만으로 예측 모델을 만들고 모델을 평가하여, 성능이 가장 좋은 N개의 feature를 선정하여 새로운 변수로 가져간다.
Feature Engineering - 2 (Features Selection)
- 학습 데이터에 랜덤 feature를 추가, 1차 학습 때의 best model로 재학습
- Feature importance를 확인했을 때, 랜덤 feature보다 중요도가 낮은 feature를 제거
2차 학습
- Feature Engineering이 끝난 feature로 하이퍼 파라미터 튜닝
- 앙상블, 스태킹 모델 생성
성능


Feature Engineering 이전 LGBM와 CBoost의 정확도는 각각 86.45%와 86.3%


Feature Engineering 이후 각각의 정확도는 87.25%, 86.85%으로 이전보다 약간 개선이 된 것을 확인할 수 있다.
Autogluon VS mljar
성능 비교
- 데이터: class 예측 데이터의 테스트 데이터 중 4000개를 훈련, 1000개를 평가
test_data = pd.read_csv('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
train_data = test_data.sample(4000, random_state=42)
test_data = test_data.drop(train_data.index).sample(1000, random_state=42)
| autogluon | mljar |
 medium_quality |
 Explain |
 good_quality |
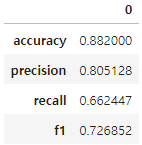 Perform |
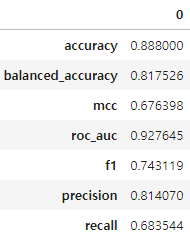 high_quality |
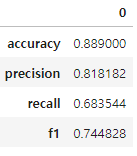 Compete |
 best_quality |
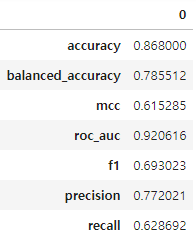
- 데이터의 종류마다 결과는 다를 수 있지만 이 데이터에서는 정확도로 보나 f1으로 보나 mljar의 판정승
- (참고1) 일반적인 RandomForest, XGBoost, LGBM의 예측 정확도는 각각 86.4%, 87.1%와 88.3%로 automl이 약간 더 좋은 성능을 보인다.
- (참고2) 2년 전에 회귀 모델로 실험했을 때는 autogluon이 약간 더 좋았다.
편의성 비교
- feature importance나 shap 등 여러 방면에서 mljar가 더 많은 정보를 제공한다.
- autogluon은 AWS에서 개발한 툴이기 때문에 SageMaker에 빠르게 적용할 수 있다는 장점이 있다.
AutoML 툴의 장단점
장점
- 코드 단 몇 줄로 데이터 전처리(혹은 피처 엔지니어링), 모델 학습, 하이퍼 파라미터 튜닝, 모델 저장, 모델 평가, 피처 중요도 등 거의 모든 예측 모델 수행에 필요한 과정을 할 수 있다.
- 일반적인 모델보다 성능이 뛰어나다.
단점
- 오래 걸린다. (클라우드 서비스 이용 시 과도한 요금 문제가 발생할 수 있다.)
- 관리를 해주지 않으면 용량을 많이 차지한다.
- 당연한 말이겠지만 커스텀이 어렵다.
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| shap 명목형 변수 표기 방법 바꾸기 (0) | 2024.05.21 |
|---|---|
| 선형회귀로 시계열 예측 모델 만들 때 조심할 점 (0) | 2024.04.16 |
| Regression - IBUG 알고리즘 논문 읽기 (0) | 2024.02.27 |
| 상관 관계의 종류 및 python 코드 구현 (0) | 2024.02.19 |
| 두 개의 분포를 보이는 데이터에 적합한 회귀 모델 만들어보기 (python) (0) | 2024.02.07 |



