분류 모델의 shap value를 확률값으로 확인하기
- 목차
반응형
1. 배경 상황
shapley value는 설명 가능한 AI(XAI) 중 하나로 모델이 "왜" 그렇게 예측을 했는지를 설명해주는 방법이다. python의 `shap` 라이브러리를 이용하여 계산할 수 있다.
shapley value는 분류 모델과 회귀 모델 둘 다 계산할 수 있는데, 이 중 분류 모델의 경우 아래와 같이 확률 예측 범위(0~1)를 벗어난 값을 보여준다.


위는 소득 분류 데이터를 XGBoost로 학습하여 class가 1인 데이터에 대한 이미지다. 이 이미지를 해석하면
전체 데이터에 대한 기댓값 -1.443에 비해 특정 데이터에 대한 예측 값은 -0.223이었고, 그렇게 되는데 영향을 주는 건 relationship, marital-status 순이다. 그 둘은 양의 영향을 주었다.
난 분명 이진 분류 모델에 대해 만들었지 회귀 모델을 만들지 않았는데 기댓값과 예측값이 음수로 나왔다. 왜 이런 걸까?
2. logit 때문
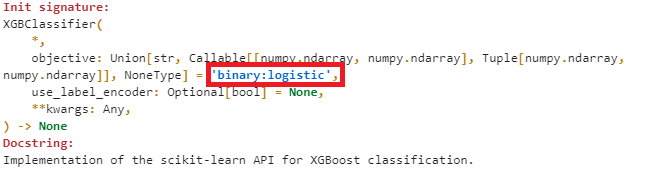
왜냐하면 shap을 계산할 때 확률이 아닌 logit을 기반으로 하기 때문이다. 참고로 XGBoost 등 일반적인 분류 모델들의 목적 함수(objective) 기본값은 logit이다.
3. 확률로 변환하기
원인을 알았다. 그럼 확률로는 어떻게 바꿀 수 있을까?
크게 두 가지 방법이 있다.
1. force plot의 경우
`link="logit"` 파라미터를 추가한다.
shap.initjs()
shap.plots.force(want_to_show, link='logit')
2. 모든 경우 (shap value를 계산할 때부터 확률을 사용하기)
waterfall plot을 비롯하여 force plot 등 모든 경우에 대해 사용할 수 있다.
`explainer`를 정의할 때 `model_output='probability'` 파라미터를 추가한다. (이 때, `data` 파라미터도 반드시 함께 넣어줘야 한다.)
explainer = shap.TreeExplainer(model, data=X_test, model_output='probability')
shap_values = explainer(X_test)
idx = 17
want_to_show = shap_values[idx]
shap.plots.waterfall(want_to_show)

force plot에는 `link` 파라미터를 주지 않아도 된다.
shap.initjs()
shap.plots.force(want_to_show)
4. 전체 코드
728x90
반응형
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| 2025 KBO MVP 예측 (by. 머신러닝 with XAI) (0) | 2025.10.28 |
|---|---|
| 2024 KBO MVP를 선수 스탯을 통해 머신러닝으로 예측해보기 (0) | 2024.10.12 |
| shap 명목형 변수 표기 방법 바꾸기 (0) | 2024.05.21 |
| 선형회귀로 시계열 예측 모델 만들 때 조심할 점 (0) | 2024.04.16 |
| AutoML, Autogluon vs mljar-supervised (0) | 2024.02.29 |


